Measuring and Applying Invalid SSL Certificates: The Silent Majority
Taejoong Chung,
Yabing Liu,
David Choffnes,
Dave Levin,
Bruce Maggs,
Alan Mislove,
Christo Wilson
Paper Overview
SSL and TLS are used to secure the most commonly used Internet protocols. As a result, the ecosystem of SSL certificates has been thoroughly studied, leading to a broad understanding of the strengths and weaknesses of the certificates accepted by most web browsers. Prior work has naturally focused almost exclusively on “valid” certificates—those that standard browsers accept as well-formed and trusted—and has largely disregarded certificates that are otherwise "invalid." Surprisingly, however, this leaves the majority of certificates unexamined: we find that, on average, 65% of SSL certificates advertised in each IPv4 scan that we examine are actually invalid. In this paper, we demonstrate that despite their invalidity, much can be understood from these certificates. Specifically, we show why the web’s SSL ecosystem is populated by so many invalid certificates, where they originate from, and how they impact security. Using a dataset of over 80M certificates, we determine that most invalid certificates originate from a few types of end-user devices, and possess dramatically different properties than their valid counterparts. We find that many of these devices periodically reissue their (invalid) certificates, and develop new techniques that allow us to track these reissues across scans. We present evidence that this technique allows us to uniquely track over 6.7M devices. Taken together, our results open up a heretofore largely-ignored portion of the SSL ecosystem to further study.
This paper was published at IMC'2016 (Internet Measurement Conference) and you can download our paper here
What is an Invalid Certificate?
The X.509 RFC defines a certificate as invalid if a client is unable to validate it at some point in time. There are multiple reasons that a client could find a certificate to be invalid: it could be outside of its validity period, it could have been revoked by its CA, its subject could be incorrect, its signature could be wrong, and so on. Because our dataset spans years (§4), we define a certificate as invalid if no client with a standard set of root certificates would ever be able to validate it (i.e., we ignore expiry warnings). The most common reason for invalidity that we have observed is certificates signed by an unknown or untrusted root; if the client does not trust the root of a certificate chain, it transitively does not trust the rest of the chain. Specifically, in our dataset, we found that 88.0% of invalid certificates are self-signed (i.e., the root of the chain is the leaf certificate itself) and a further 11.99% are signed by a different, untrusted certificate (i.e., the root of the chain is some other certificate that is not in the set of trusted root certificates).
Dataset
We obtain our collection of SSL certificates from two sets of full IPv4 port 443 scans. Our first dataset was collected by the University of Michigan, with 156 scans conducted between June 10, 2012 and January 29, 2014. These scans were not conducted at regular intervals: while there were an average 3.83 days between scans, there were periods of up to 24 days with no scans at all, as well as a set of 42 sequential days during which we have daily scans. Our second dataset was collected by Rapid7, with 74 scans conducted between October 30, 2013 and March 30, 2015 (an average of 7.73 days between scans). Unlike the University of Michigan scans, the Rapid7 scans were almost always conducted seven days apart. On eight days, both datasets have scans, resulting in scans on 222 unique days. The scans found an average of 28M unique IP addresses responding to SSL handshakes per scan, and a total of 192M unique IP addresses responding to SSL handshakes across all scans (4.49% of the entire IPv4 address space). Across all scans, we observe 80,366,826 unique certificates; 39,147,006 of these are version 3 leaf certificates, 28,997,853 are version 3 CA certificates, and 12,132,294 are version 1 certificates.Dataset Inconsistency
While both datasets claim to be full IPv4 scans, we observed that the two scans actually had different sizes: the Rapid7 scans consistently contained approximately 20% fewer IP addresses than the University of Michigan scans. Looking more closely, we found that the Rapid7 scans were not a strict subset of the University of Michigan scans: there were also a significant number of IP addresses that only appeared in the Rapid7 scans. The figure below (Figure 1) selects one of the days where both data sources have a scan, and plots the fraction of hosts in each /8 network that only appear in one of the scans. We can immediately observe that the "missing" hosts from each scan appear to be spread across the entire IP space.6 After communicating this observation to Rapid7, they were unable to track down the source of this discrepancy.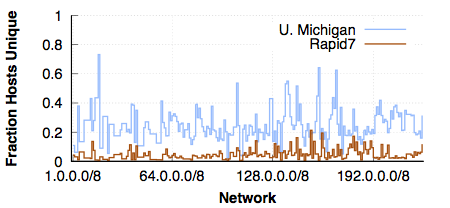
[Figure 1] The fraction of hosts unique to each scan, for each /8 network, on a day with both a University of Michigan and a Rapid7 scan. The “missing” hosts in each scan appear to be spread throughout the IP space.
The figure below (Figure 2) shows the full /8 analysis of discrepancy between University of Michigan and a Rapid7 scan. For our total measurement period, we grouped the IP addresses into their advertised BGP prefixes using historic RouteViews data and compared each BGP prefixes one could cover but the other couldn't; If neither datasets were able to scan some prefixes, the regions are colored gray, if only University of Michigan dataset could scan, they are colored green, and if only Rapid7 could do, they are colored red.
We believe this is due to black-listing by either the scan operators or the target networks (Rapid7 confirmed to us that they have a growing list of networks that requested to not be scanned). You also can see our numeric analysis about BGP prefixes in our paper.
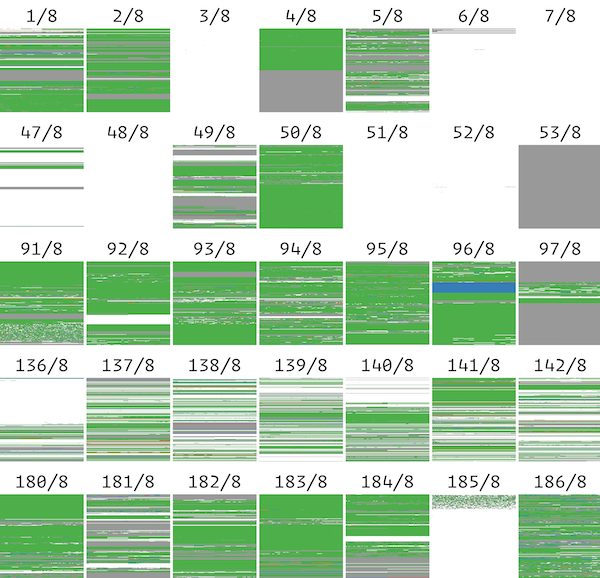
[Figure 2] An example of /8 BGP Prefixes that one dataset could cover, but the other couldn't
Click to see full list of /8 network analysis{kind=link}
Processed Dataset
From merged two datasets, we extracted various field information (e.g., public key, common name, and etc.) from certificates and built a tsv (tab-separated-version) file. We also verified each certificates to see whether they are valid or not and classified them into two files: invalid-certs.tsv and valid-certs.tsv. These two files were used for all our analysis. You can find all the details regarding fields of a certificate that we extracted in "Description".| Name | Type | Size | SHA-256 Hash (Uncompressed) |
|---|---|---|---|
| Invalid Certificates | tsv (tab separated version) | 65 GB | 87afe4f2d9c0901d607ee2bb0fc2a77e3a043470b2ed1a09df628a069e9fb62b |
| Valid Certificates | tsv (tab separated version) | 28 GB | f015814146b49afd38a43c05f3f1a3d9a841361f4fa1338dc07745f2de1b4b0d |
| Description | txt | 1.5 KB | b61bc1dacb7168b13fdf1aab089250edcfb7029e89b41de73b7c729d9f081e71 |
Linking Invalid Certificates
The details of procedures how we classified invalid certificates that we can link is described on the paper. But what we basically did is linking multiple invalid certificates to one device by leveraging (1) multiple shared common field values (which are supposed to be unique) between each different certificates, and (2) lifetime of the certificates (i.e., lifetime of new (reissued) certificate and old (replaced) certificate MUST NOT overlap).| Name | Type | Description |
|---|---|---|
| Comparison btw. Invalid and Valid certificates | perl | Exporting basic statistics of each fields in certificates. |
| Linking Certificates | python | Linking multiple certificates having common field value and non-overlapping lifetime. |
| Cascade Linking Certificates | python | Iteratively linking multiple certificates using all possible field values. Linking conditions are same as above one. |
Contact
Do you have any questions, comments or concern? Feel free to send us an email to Taejoong Chung